Machine learning models are rapidly becoming more capable; how can we make use of these powerful new tools in our Go applications?
For top-of-the-line commercial LLMs like ChatGPT, Gemini or Claude, the models are exposed as language agnostic REST APIs. We can hand-craft HTTP requests or use client libraries (SDKs) provided by the LLM vendors. If we need more customized solutions, however, some challenges arise. Completely bespoke models are typically trained in Python using tools like TensorFlow, JAX or PyTorch that don't have real non-Python alternatives.
In this post, I will present some approaches for Go developers to use ML models in their applications - with increasing level of customization. The summary up front is that it's pretty easy, and we only have to deal with Python very minimally, if at all - depending on the circumstances.

Internet LLM services
This is the easiest category: multimodal services from Google, OpenAI and others are available as REST APIs with convenient client libraries for most leading languages (including Go), as well as third-party packages that provide abstractions on top (e.g. langchaingo).
Check out the official Go blog titled Building LLM-powered applications in Go that was published earlier this year. I've written about it before on this blog as well: #1, #2, #3 etc.
Go is typically as well supported as other programming languages in this domain; in fact, it's uniquely powerful for such applications because of its network-native nature; quoting from the Go blog post:
Working with LLM services often means sending REST or RPC requests to a network service, waiting for the response, sending new requests to other services based on that and so on. Go excels at all of these, providing great tools for managing concurrency and the complexity of juggling network services.
Since this has been covered extensively, let's move on to the more challenging scenarios.
Locally-running LLMs
There's a plethora of high-quality open models [1] one can choose from to run locally: Gemma, Llama, Mistral and many more. While these models aren't quite as capable as the strongest commercial LLM services, they are often surprisingly good and have clear benefits w.r.t. cost and privacy.
The industry has begun standardizing on some common formats for shipping and sharing these models - e.g. GGUF from llama.cpp, safetensors from Hugging Face or the older ONNX. Additionally, there are a number of excellent OSS tools that let us run such models locally and expose a REST API for an experience that's very similar to the OpenAI or Gemini APIs, including dedicated client libraries.
The best known such tool is probably Ollama; I've written extensively about it in the past: #1, #2, #3.
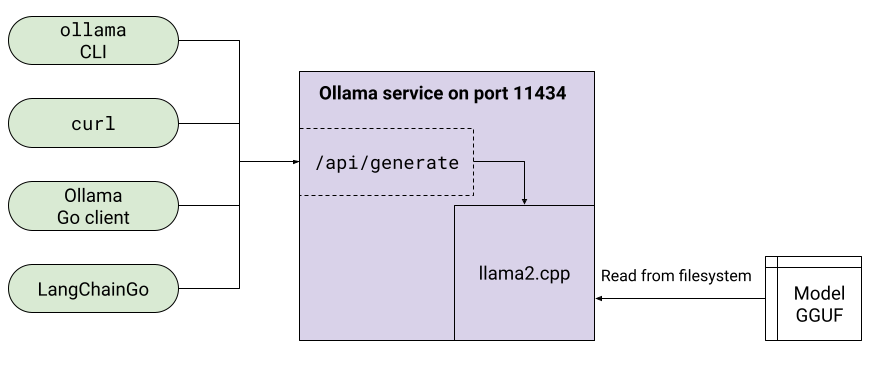
Ollama lets us customize an LLM through a Modelfile, which includes things like setting model parameters, system prompts etc. If we fine-tuned a model [2], it can also be loaded into Ollama by specifying our own GGUF file.
If you're running in a cloud environment, some vendors already have off-the-shelf solutions like GCP's Cloud Run integration that may be useful.
Ollama isn't the only player in this game, either; recently a new tool emerged with a slightly different approach. Llamafile distributes the entire model as a single binary, which is portable across several OSes and CPU architectures. Like Ollama, it provides REST APIs for the model.
If such a customized LLM is a suitable solution for your project, consider just running Ollama or Llamafile and using their REST APIs to communicate with the model. If you need higher degrees of customization, read on.
A note about the sidecar pattern
Before we proceed, I want to briefly discuss the sidecar pattern of application deployment. That k8s link talks about containers, but the pattern isn't limited to these. It applies to any software architecture in which functionality is isolated across processes.
Suppose we have an application that requires some library functionality; using Go as an example, we could find an appropriate package, import it and be on our way. Suppose there's no suitable Go package, however. If libraries exist with a C interface, we could alternatively use cgo to import it.
But say there's no C API either, for example if the functionality is only provided by a language without a convenient exported interface. Maybe it's in Lisp, or Perl, or... Python.
A very general solution could be to wrap the code we need in some kind of server interface and run it as a separate process; this kind of process is called a sidecar - it's launched specifically to provide additional functionality for another process. Whichever inter-process communication (IPC) mechanism we use, the benefits of this approach are many - isolation, security, language independence, etc. In today's world of containers and orchestration this approach is becoming increasingly more common; this is why many of the links about sidecars lead to k8s and other containerized solutions.

The Ollama approach outlined in the previous section is one example of using the sidecar pattern. Ollama provides us with LLM functionality but it runs as a server in its own process.
The solutions presented in the rest of this post are more explicit and fully worked-out examples of using the sidecar pattern.
Locally-running LLM with Python and JAX
Suppose none of the existing open LLMs will do for our project, even fine-tuned. At this point we can consider training our own LLM - this is hugely expensive, but perhaps there's no choice. Training usually involves one of the large ML frameworks like TensorFlow, JAX or PyTorch. In this section I'm not going to talk about how to train models; instead, I'll show how to run local inference of an already trained model - in Python with JAX, and use that as a sidecar server for a Go application.
The sample (full code is here) is based on the official Gemma repository, using its sampler library [3]. It comes with a README that explains how to set everything up. This is the relevant code instantiating a Gemma sampler:
# Once initialized, this will hold a sampler_lib.Sampler instance that
# can be used to generate text.
gemma_sampler = None
def initialize_gemma():
"""Initialize Gemma sampler, loading the model into the GPU."""
model_checkpoint = os.getenv("MODEL_CHECKPOINT")
model_tokenizer = os.getenv("MODEL_TOKENIZER")
parameters = params_lib.load_and_format_params(model_checkpoint)
print("Parameters loaded")
vocab = spm.SentencePieceProcessor()
vocab.Load(model_tokenizer)
transformer_config = transformer_lib.TransformerConfig.from_params(
parameters,
cache_size=1024,
)
transformer = transformer_lib.Transformer(transformer_config)
global gemma_sampler
gemma_sampler = sampler_lib.Sampler(
transformer=transformer,
vocab=vocab,
params=parameters["transformer"],
)
print("Sampler ready")
The model weights and tokenizer vocabulary are files downloaded from Kaggle, per the instructions in the Gemma repository README.
So we have LLM inference up and running in Python; how do we use it from Go?
Using a sidecar, of course. Let's whip up a quick web server around this model and expose a trivial REST interface on a local port that Go (or any other tool) can talk to. As an example, I've set up a Flask-based web server around this inference code. The web server is invoked with gunicorn - see the shell script for details.
Excluding the imports, here's the entire application code:
def create_app():
# Create an app and perform one-time initialization of Gemma.
app = Flask(__name__)
with app.app_context():
initialize_gemma()
return app
app = create_app()
# Route for simple echoing / smoke test.
@app.route("/echo", methods=["POST"])
def echo():
prompt = request.json["prompt"]
return {"echo_prompt": prompt}
# The real route for generating text.
@app.route("/prompt", methods=["POST"])
def prompt():
prompt = request.json["prompt"]
# For total_generation_steps, 128 is a default taken from the Gemma
# sample. It's a tradeoff between speed and quality (higher values mean
# better quality but slower generation).
# The user can override this value by passing a "sampling_steps" key in
# the request JSON.
sampling_steps = request.json.get("sampling_steps", 128)
sampled_str = gemma_sampler(
input_strings=[prompt],
total_generation_steps=int(sampling_steps),
).text
return {"response": sampled_str}
The server exposes two routes:
- prompt: a client sends in a textual prompt, the server runs Gemma inference and returns the generated text in a JSON response
- echo: used for testing and benchmarking
Here's how it all looks tied together:

The important takeaway is that this is just an example. Literally any part of this setup can be changed: one could use a different ML library (maybe PyTorch instead of JAX); one could use a different model (not Gemma, not even an LLM) and one can use a different setup to build a web server around it. There are many options, and each developer will choose what fits their project best.
It's also worth noting that we've written less than 100 lines of Python code in total - much of it piecing together snippets from tutorials. This tiny amount of Python code is sufficient to wrap an HTTP server with a simple REST interface around an LLM running locally through JAX on the GPU. From here on, we're safely back in our application's actual business logic and Go.
Now, a word about performance. One of the concerns developers may have with sidecar-based solutions is the performance overhead of IPC between Python and Go. I've added a simple echo endpoint to measure this effect; take a look at the Go client that exercises it; on my machine the latency of sending a JSON request from Go to the Python server and getting back the echo response is about 0.35 ms on average. Compared to the time it takes Gemma to process a prompt and return a response (typically measured in seconds, or maybe hundreds of milliseconds on very powerful GPUs), this is entirely negligible.
That said, not every custom model you may need to run is a full-fledged LLM. What if your model is small and fast, and the overhead of 0.35 ms becomes significant? Worry not, it can be optimized. This is the topic of the next section.
Locally-running fast image model with Python and TensorFlow
The final sample of this post mixes things up a bit:
- We'll be using a simple image model (instead of an LLM)
- We're going to train it ourselves using TensorFlow+Keras (instead of JAX)
- We'll use a different IPC method between the Python sidecar server and clients (instead of HTTP+REST)
The model is still implemented in Python, and it's still driven as a sidecar server process by a Go client [4]. The idea here is to show the versatility of the sidecar approach, and to demonstrate a lower-latency way to communicate between the processes.
The full code of the sample is here. It trains a simple CNN (convolutional neural network) to classify images from the CIFAR-10 dataset:

The neural net setup with TensorFlow and Keras was taken from an official tutorial. Here's the entire network definition:
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation="relu", input_shape=(32, 32, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation="relu"))
model.add(layers.Flatten())
model.add(layers.Dense(64, activation="relu"))
model.add(layers.Dense(10))
CIFAR-10 images are 32x32 pixels, each pixel being 3 values for red, green and blue. In the original dataset, these values are bytes in the inclusive range 0-255 representing color intensity. This should explain the (32, 32, 3) shape appearing in the code. The full code for training the model is in the train.py file in the sample; it runs for a bit and saves the serialized model along with the trained weights into a local file.
The next component is an "image server": it loads the trained model+weights file from disk and runs inference on images passed into it, returning the label the model thinks is most likely for each.
The server doesn't use HTTP and REST, however. It creates a Unix domain socket and uses a simple length-prefix encoding protocol to communicate:

Each packet starts with a 4-byte field that specifies the length of the rest of the contents. A type is a single byte, and the body can be anything [5]. In the sample image server two commands are currently supported:
- 0 means "echo" - the server will respond with the same packet back to the client. The contents of the packet body are immaterial.
- 1 means "classify" - the packet body is interpreted as a 32x32 RGB image, encoded as the red channel for each pixel in the first 1024 bytes (32x32, row major), then green in the next 1024 bytes and finally blue in the last 1024 bytes. Here the server will run the image through the model, and reply with the label the model thinks describes the image.
The sample also includes a simple Go client that can take a PNG file from disk, encode it in the required format and send it over the domain socket to the server, recording the response.
The client can also be used to benchmark the latency of a roundtrip message exchange. It's easier to just show the code instead of explaining what it does:
func runBenchmark(c net.Conn, numIters int) {
// Create a []byte with 3072 bytes.
body := make([]byte, 3072)
for i := range body {
body[i] = byte(i % 256)
}
t1 := time.Now()
for range numIters {
sendPacket(c, messageTypeEcho, body)
cmd, resp := readPacket(c)
if cmd != 0 || len(resp) != len(body) {
log.Fatal("bad response")
}
}
elapsed := time.Since(t1)
fmt.Printf("Num packets: %d, Elapsed time: %s\n", numIters, elapsed)
fmt.Printf("Average time per request: %d ns\n", elapsed.Nanoseconds()/int64(numIters))
}
In my testing, the average latency of a roundtrip is about 10 μs (that's micro-seconds). Considering the size of the message and it being Python on the other end, this is roughly in-line with my earlier benchmarking of Unix domain socket latency in Go.
How long does a single image inference take with this model? In my measurements, about 3 ms. Recall that the communication latency for the HTTP+REST approach was 0.35 ms; while this is only 12% of the image inference time, it's close enough to be potentially worrying. On a beefy server-class GPU the time can be much shorter [6].
With the custom protocol over domain sockets, the latency - being 10 μs - seems quite negligible no matter what you end up running on your GPU.
Code
The full code for the samples in this post is on GitHub.
| [1] | To be pedantic, these models are not entirely open: their inference architecture is open-source and their weights are available, but the details of their training remain proprietary. |
| [2] | The details of fine-tuning models are beyond the scope of this post, but there are plenty resources about this online. |
| [3] | "Sampling" in LLMs means roughly "inference". A trained model is fed an input prompt and then "sampled" to produce its output. |
| [4] | In my samples, the Python server and Go client simply run in different terminals and talk to each other. How service management is structured is very project-specific. We could envision an approach wherein the Go application launches the Python server to run in the background and communicates with it. Increasingly likely these days, however, would be a container-based setup, where each program is its own container and an orchestration solution launches and manages these containers. |
| [5] | You may be wondering why I'm implementing a custom protocol here instead of using something established. In real life, I'd definitely recommend using something like gRPC. However, for the sake of this sample I wanted something that would be (1) simple without additional libraries and (2) very fast. FWIW, I don't think the latency numbers would be very much different for gRPC. Check out my earlier post about RPC over Unix domain sockets in Go. |
| [6] | On the other hand, the model I'm running here is really small. It's fair to say realistic models you'll use in your application will be much larger and hence slower. |