In a previous post I've described how - thanks to standardized tooling - we could use a locally-running Gemma model from a Go program within hours from its public release.
This post dives into the internals of Ollama - a popular and extremely convenient open-source Go project that makes such workflows possible.

HTTP request to Ollama
Having installed Ollama and run ollama run gemma, we're ready to send HTTP requests to it. There are several ways to do so:
- Sending a raw HTTP request with a tool like curl
- Using Ollama's own client libraries (currently available in Go, Python and JS)
- Using a provider-agnostic client like LangChainGo
For options (2) and (3) see the Appendix; here we'll focus on (1) for simplicity and to remove layers from the explanation.
Let's send an HTTP request to the api/generate endpoint of Ollama with curl:
$ curl http://localhost:11434/api/generate -d '{
"model": "gemma",
"prompt": "very briefly, tell me the difference between a comet and a meteor",
"stream": false
}' | jq .
[...]
{
"model": "gemma",
"created_at": "2024-03-04T14:43:51.665311735Z",
"response": "Sure, here is the difference between a comet and a meteor:
**Comet:**
- A celestial object that orbits the Sun in a highly elliptical path.
- Can be seen as a streak of light in the sky, often with a tail.
- Comets typically have a visible nucleus, meaning a solid core that
can be seen from Earth.
**Meteor:**
- A streak of hot gas or plasma that appears to move rapidly across the sky.
- Can be caused by small pieces of rock or dust from space that burn up
in the atmosphere.
- Meteors do not have a visible nucleus.",
"done": true,
"context":
[...]
}
(The response is JSON and I've reformatted the text for clarity)
Ollama's HTTP API is documented here. For each endpoint, it lists a description of parameters and the data returned.
Ollama service
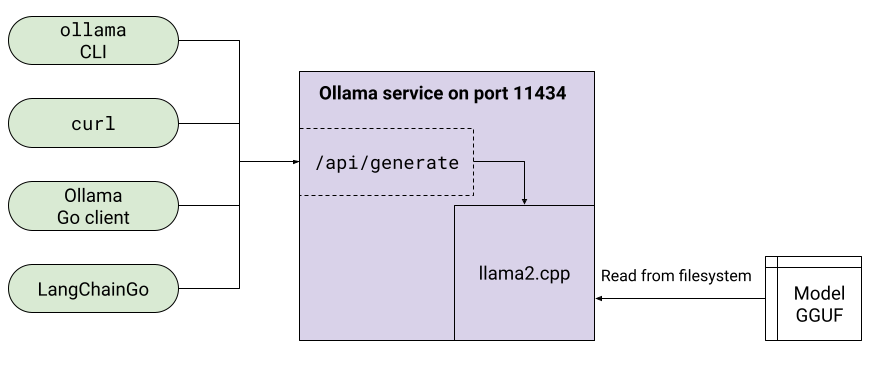
Ollama itself is a client-server application; when the installation script is run, it does several things:
- Download Ollama binary
- Place it in $PATH
- Run ollama serve as a background service
The service checks the value of the OLLAMA_HOST env var to figure out which host and port to use. The default is port 11434 on localhost (hence you can see our curl request is made to localhost:11434). It then listens on the port, presenting the API discussed above.
What's interesting to note is that when we run ollama run <model> from the command-line, this invokes the Ollama binary in client mode; in this mode, it sends requests to the service using the same API. For example, here are two ways to invoke it - interactive:
$ ollama run gemma
>>> translate naranjo to english
Naranjo translates to Orange in English.
Naranjo is the Spanish word for Orange.
>>> <Ctrl+D>
And piping to stdin:
$ echo "translate naranjo to english" | ollama run gemma
Naranjo translates to Orange in English. Orange is the English word equivalent of the word Naranjo.
In both these cases, the Ollama binary sends an HTTP request to http://localhost:11434/api/generate, just like the one we've made manually with curl.
The generate API endpoint
Now that we know where our prompt to Ollama ends up (whether we issue it using an HTTP request or the Ollama command-line tool), let's see what the generate API endpoint actually does.
Ollama uses the Gin web framework, and the API route is fairly standard:
r.POST("/api/generate", GenerateHandler)
This routes HTTP POST requests for /api/generate to a handler function called GenerateHandler, which is defined in the same source file:
func GenerateHandler(c *gin.Context) {
[...]
}
After parsing and validating the request, GenerateHandler starts by fetching the model the request asked for with the "model" field. It then loads the right model and runs it, feeding it with the prompt provided in the request. The next sections describe these two steps.
Fetching and loading the model
When Ollama is looking for a model (by name), it first checks if it already has it downloaded and stored locally. On my Linux machine, Ollama stores its local cache of models at /usr/share/ollama/.ollama/models/blobs. If the model is already available locally, there's not much to do for this step.
Otherwise, Ollama looks in its online library of models. Specifically, the service makes a request to https://registry.ollama.ai/v2/library/ to check if a model exists. At the time of writing, it's not clear if anyone except the Ollama maintainers can upload new models to the library - but it seems like they're working on this option.
But where do these models come from? As this doc explains, models are imported from other sources in formats like GGUF or Safetensors. The topic of these formats is very interesting, but I won't be covering it in this post; if you're interested, a recent blog post by Vicki Boykis provides useful historic background.
While models can be imported from a variety of formats, Ollama's library stores them as GGUF and that's what the service expects to find.
For the purpose of this explanation, it's sufficient to know that GGUF stores some metadata about the model (e.g. its architecture and parameters, like numbers of layers in different parts, etc) as well as its actual weights. The weights can be stored in different formats - some more suitable for GPUs, some for CPUs. Quantization is common, especially for CPU-oriented models. The model file is usually a giant multi-GiB binary blob that needs to be downloaded and cached locally.
Running the underlying model with a prompt
To run the model, Ollama turns to another project - llama.cpp. llama.cpp arose as a local inference engine for the Llama model when it was originally released. Since the model architecture and weights were published, it became possible to implement inference for the model without relying on full-blown Python ML frameworks like TensorFlow, PyTorch or JAX. It uses its author's separate project - ggml, for an efficient C++ library of ML primitives that can run on CPUs and GPUs.
Originally llama.cpp just hard-coded Llama's architecture and loaded the weights, but in time it grew to incorporate additional open-sourced models and its implementation became a kind of a switch based on the model's architecture.
For example, this commit added Gemma support to llama.cpp [1]. Once this is in place, all it needs is to load the weights and some parameterization of the model from its GGUF file and it's ready to go.
llama.cpp is a C++ project that was originally designed as a command-line utility you can use to load models and chat with them. C++ is not known for having a pleasant or stable ABI to work with, so many projects wrapped llama.cpp with a lightweight C ABI in order to create bindings into other languages.
Ollama, as a Go project, did the same. It went a step further though, and cleverly leverages llama.cpp's server sample, which encapsulates all operations in functions that take JSON inputs and return JSON outputs. Ollama added some glue in ext_server, and wrapped it with cgo to be able to invoke llama.cpp inference in-process.
The generate endpoint calls llm.Predict, which after some hops ends llama.cpp's request_completion.
Afterword: standard interfaces
In my previous post, I've mentioned that the flow works and is easy to set up due to standardized interfaces that have been implemented in OSS projects.
After reading this post with Ollama internals, I hope it's clear what standardized interfaces come into play here.
First and foremost is llama.cpp and its associated GGUF format. While the internals of llama.cpp are somewhat clunky, this project is unapologetically pragmatic and a true boon for the ecosystem because of the way it standardizes LLM inference (and embeddings). Given a model architecture implemented in C++ in the innards of llama.cpp, variations can be easily explored and run on compatible CPUs and GPUs. Slight model modifications? Tuning? Trying some new kind of quantizations? Just create a GGUF file and llama.cpp will run it for you.
The other half of the solution is Ollama, which wraps llama.cpp in a conveniently packaged tool, API and ecosystem [2]. As a Go project, it's easily distributable and makes it trivial to hack on a powerful API server. The REST API it presents can then be leveraged by any tool capable of issuing HTTP requests.
Appendix: Go client libraries for the Ollama API
If you want to use LLMs programmatically from Go through Ollama, the most convenient options are either using Ollama's own Go client library or through LangChainGo. Another option - as discussed above - is to send raw HTTP requests.
The Ollama Go client library is a great option because it's what the Ollama client itself uses to talk to the service; it's as battle-tested and functional as you can hope for. On the other hand, LangChainGo is convenient if you use multiple providers and want code that's consistent and provider-agnostic.
This sample lists Go code to ask Ollama a question using (1) the Ollama Go library or (2) LangChainGo.
| [1] | The Gemma announcement points to this official documentation and implementation - https://github.com/google-deepmind/gemma - it can be used to re-implement Gemma inference, along with the pre-trained model weights Google released. |
| [2] | Ollama has additional capabilities I haven't mentioned here, like Modelfiles for creating and sharing models. |