A few months ago I wrote a post on formulating the Normal Equation for linear regression. A crucial part in the formulation is using matrix calculus to compute a scalar-by-vector derivative. I didn't spend much time explaining how this step works, instead remarking:
Deriving by a vector may feel uncomfortable, but there's nothing to worry about. Recall that here we only use matrix notation to conveniently represent a system of linear formulae. So we derive by each component of the vector, and then combine the resulting derivatives into a vector again.
According to the comments received on the post, folks didn't find this convincing and asked for more details. One commenter even said that "matrix calculus feels handwavy", something which I fully agree with. The reason matrix calculus feels handwavy is that it's not as commonly encountered as "regular" calculus, and hence its identities and intuitions are not as familiar. However, there's really not that much to it, as I want to show here.
Let's get started with a simple example, which I'll use to demonstrate the principles. Say we have the function:
![\[f(v)=a^Tv\]](https://eli.thegreenplace.net/images/math/94f87149715376908db65a00f793836a4b2092a9.png)
Where a and v are vectors with n components [1]. We want to compute its derivative by v. But wait, while a "regular" derivative by a scalar is clearly defined (using limits), what does deriving by a vector mean? It simply means that we derive by each component of the vector separately, and then combine the results into a new vector [2]. In other words:
![\[\frac{\partial f}{\partial v}=\begin{pmatrix}\frac{\partial f}{\partial v_1}\\[1em] \frac{\partial f}{\partial v_2}\\ ...\\ \frac{\partial f}{\partial v_n}\\[1em] \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/13d227107c5323f47460ad077504fda60726d933.png)
Let's see how this works out for our function f. It may be more convenient to rewrite it by using components rather than vector notation:
![\[f(v)=a^Tv=a_1v_1+a_2v_2+...+a_nv_n\]](https://eli.thegreenplace.net/images/math/e9e17e44bb85d825f304b09247a7f3cfbe11f64e.png)
Computing the derivatives by each component, we'll get:
![\[\begin{matrix}\frac{\partial f}{\partial v_1}=a_1\\[1em] \frac{\partial f}{\partial v_2}=a_2\\ ...\\ \frac{\partial f}{\partial v_n}=a_n\\[1em] \end{matrix}\]](https://eli.thegreenplace.net/images/math/768563e5b7e2e8cddd00830e9b945419f598e4bb.png)
So we have a sequence of partial derivatives, which we combine into a vector:
![\[\frac{\partial f}{\partial v}=\begin{pmatrix}a_1\\ ...\\ a_n\\ \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/b13cc64568603d73240709c1fb49cfcc7f2a2b62.png)
Or, in other words 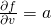 .
.
This example demonstrates the algorithm for computing scalar-by-vector derivatives:
- Figure out what the dimensions of all vectors and matrices are.
- Expand the vector equations into their full form (a multiplication of two vectors is either a scalar or a matrix, depending on their orientation, etc.) Note that this will end up with a scalar.
- Compute the derivative of the scalar by each component of the variable vector separately.
- Combine the derivatives into a vector.
Similarly to regular calculus, matrix and vector calculus rely on a set of
identities to make computations more manageable. We can either go the hard way
(computing the derivative of each function from basic principles using limits),
or the easy way - applying the plethora of convenient identities that were
developed to make this task simpler. The identity for computing the derivative
of 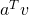 shown above plays the role of
shown above plays the role of 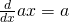 in
regular calculus.
in
regular calculus.
Now we have the tools to understand how the vector derivatives in the normal equation article were computed. As a reminder, this is the matrix form of the cost function J:
![\[J(\theta)=\theta^TX^TX\theta-2(X\theta)^Ty+y^Ty\]](https://eli.thegreenplace.net/images/math/2864b88546c007a79dc92271f5e01487ba608e43.png)
And we're interested in computing 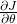 .
The equation for J consists of three terms added together. The last one
.
The equation for J consists of three terms added together. The last one
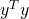 doesn't contribute to the derivative because it doesn't depend on
the variable. Let's start looking at the second (since it's simpler than the
first) - and give it a name, for convenience:
doesn't contribute to the derivative because it doesn't depend on
the variable. Let's start looking at the second (since it's simpler than the
first) - and give it a name, for convenience:
![\[P(\theta)=2(X\theta)^Ty\]](https://eli.thegreenplace.net/images/math/35d3ddf05898e8bc2085030aa399ce98318674f9.png)
We'll start by recalling what all the dimensions are. 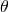 is a vector
of n components.
is a vector
of n components. 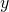 is a vector of m components.
is a vector of m components. 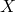 is a m-by-n
matrix.
is a m-by-n
matrix.
Let's see what P expands to [3]:
![\[P(\theta)=2\left [ \begin{pmatrix} x_1_1 & x_1_2 & ... & x_1_n\\ x_2_1 & ... & ... & x_2_n\\ ...\\ x_m_1 & ... & ... & x_m_n\\ \end{pmatrix}\begin{pmatrix} \theta_1\\ \theta_2\\ ...\\ \theta_n\\ \end{pmatrix} \right ]^T\begin{pmatrix} y_1\\ y_2\\ ...\\ y_m\\ \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/a7873ed04e274b30852e0f8d9450b5abc200ac17.png)
Computing the matrix-by-vector multiplication inside the parens:
And finally, multiplying the two vectors together:
Working with such formulae makes you appreciate why mathematicians have long ago come up with shorthand notations like "sigma" summation:
OK, so we've finally completed step 2 of the algorithm - we have the scalar
equation for P. Now it's time to compute its derivative by each
:
![\[\begin{matrix} \frac{\partial P}{\partial \theta_1}=2(x_1_1y_1+...+x_m_1y_m)\\[1em] \frac{\partial P}{\partial \theta_2}=2(x_1_2y_1+...+x_m_2y_m)\\ ...\\ \frac{\partial P}{\partial \theta_n}=2(x_1_ny_1+...+x_m_ny_m) \end{matrix}\]](https://eli.thegreenplace.net/images/math/889eb3c4e50b4fbdf5380c4d4e31ac4c0c09dddd.png)
Now comes the most interesting part. If we treat
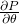 as a vector of n components, we can
rewrite this set of equations using a matrix-by-vector multiplication:
as a vector of n components, we can
rewrite this set of equations using a matrix-by-vector multiplication:
![\[\frac{\partial P}{\partial \theta}=2X^Ty\]](https://eli.thegreenplace.net/images/math/7f75aa0f038ca73c58e95ef604ffb54468a18ae2.png)
Take a moment to convince yourself this is true. It's just collecting the individual components of X into a matrix and the individual components of y into a vector. Since X is a m-by-n matrix and y is a m-by-1 column vector, the dimensions work out and the result is a n-by-1 column vector.
So we've just computed the second term of the vector derivative of J. In the
process, we've discovered a useful vector derivative identity for a matrix X
and vectors and y:
![\[\frac{\partial (X\theta)^T y}{\partial \theta}=X^Ty\]](https://eli.thegreenplace.net/images/math/bf7325787bc464f067372a6d4ed612ea514d29b6.png)
OK, now let's get back to the full definition of J and see how to compute the derivative of its first term. We'll give it the name Q:
![\[Q(\theta)=\theta^TX^TX\theta\]](https://eli.thegreenplace.net/images/math/0031acbab8dba6cef63f2605a15a0b7bc826766a.png)
This derivation is somewhat more complex, since appears twice in
the equation. Here's the equation again with all the matrices and vectors fully
laid out (note that I've already done the transposes):
![\[Q(\theta)=(\theta_1...\theta_n)\begin{pmatrix}x_1_1 & x_2_1 & ... & x_m_1\\ x_1_2 & ... & ... & x_m_2\\ ...\\ x_1_n & ... & ... & x_m_n\\ \end{pmatrix}\begin{pmatrix}x_1_1 & x_1_2 & ... & x_1_n\\ x_2_1 & ... & ... & x_2_n\\ ...\\ x_m_1 & ... & ... & x_m_n\\ \end{pmatrix}\begin{pmatrix} \theta_1\\ \theta_2\\ ...\\ \theta_n\\ \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/b3f9b4ffe1853d6610f9814fc820d1a71825a06e.png)
I'll just multiply the two matrices in the middle together. The result is a "X squared" matrix, which is n-by-n. The element in row r and column c of this square matrix is:
![\[\sum_{i=1}^{m}x_i_rx_i_c\]](https://eli.thegreenplace.net/images/math/f8628d68855e03195fb4fd01806c8655beaf7b30.png)
Note that "X squared" is a symmetric matrix (this fact will be important
later on). For simplicity of notation, we'll call its elements
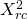 . Multiplying by the vector on the right we
get:
. Multiplying by the vector on the right we
get:
![\[Q(\theta)=(\theta_1...\theta_n)\begin{pmatrix}X^{2}_{11}\theta_1+...+X^{2}_{1n}\theta_n\\[1em] X^{2}_{21}\theta_1+...+X^{2}_{2n}\theta_n\\ ...\\ X^{2}_{n1}\theta_1+...+X^{2}_{nn}\theta_n\end{pmatrix}\]](https://eli.thegreenplace.net/images/math/5821cf256f6cf6debbdac48d6e9bbe698baa0a11.png)
And left-multiplying by to get the fully unwrapped formula for
Q:
![\[Q(\theta)=\theta_1(X^{2}_{11}\theta_1+...+X^{2}_{1n}\theta_n)+\theta_2(X^{2}_{21}\theta_1+...+X^{2}_{2n}\theta_n)+...+\theta_n(X^{2}_{n1}\theta_1+...+X^{2}_{nn}\theta_n)\]](https://eli.thegreenplace.net/images/math/0451f9fa7c61ff3a61be8c1836c15667cd916330.png)
Once again, it's now time to compute the derivatives. Let's focus on
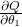 , from which we can infer the rest:
, from which we can infer the rest:
![\[\frac{\partial Q}{\partial \theta_1}=(2\theta_1X^{2}_{11}+\theta_2X^{2}_{12}+...+\theta_nX^{2}_{1n})+\theta_2X^{2}_{21}+...+\theta_nX^{2}_{n1}\]](https://eli.thegreenplace.net/images/math/f99e5e7024b4d13b0a767b98653b6ccc22fa1abd.png)
Using the fact that X squared is symmetric, we know that
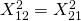 and so on. Therefore:
and so on. Therefore:
![\[\frac{\partial Q}{\partial \theta_1}=2\theta_1X^{2}_{11}+2\theta_2X^{2}_{12}+...+2\theta_nX^{2}_{1n}\]](https://eli.thegreenplace.net/images/math/832b294f472a23e500616db08d9d6832770af6a3.png)
The partial derivatives by other components are similar.
Collecting the sequence of partial derivatives back into a vector equation, we
get:
![\[\frac{\partial Q}{\partial \theta}=2X^2\theta=2X^TX\theta\]](https://eli.thegreenplace.net/images/math/541124d49fa78dcf92a15b14643b2ebc4187eaaf.png)
Now back to J. Recall that for convenience we broke J up into three parts:
P, Q and ; the latter doesn't depend on so it
doesn't play a role in the derivative. Collecting our results from this post, we
then get:
![\[\frac{\partial J}{\partial \theta}=\frac{\partial Q}{\partial \theta}-\frac{\partial P}{\partial \theta}=2X^TX\theta-2X^Ty\]](https://eli.thegreenplace.net/images/math/9c3d0d108ada3bfc7290c2328c8e6171bc01d7de.png)
Which is exactly the equation we were expecting to see.
To conclude - if matrix calculus feels handwavy, it's because its identities are
less familiar. In a sense, it's handwavy in the same way
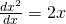 is handwavy. We remember the identity so we don't
have to recalculate it every time from first principles. Once you get some
experience with matrix calculus, parts of equations start looking familiar and
you no longer need to engage in the long and tiresome computations demonstrated
here. It's perfectly fine to just remember that the derivative of
is handwavy. We remember the identity so we don't
have to recalculate it every time from first principles. Once you get some
experience with matrix calculus, parts of equations start looking familiar and
you no longer need to engage in the long and tiresome computations demonstrated
here. It's perfectly fine to just remember that the derivative of
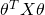 with a symmetric X is
with a symmetric X is 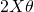 . See the
"identities" section of the wikipedia article on matrix calculus for many more examples.
. See the
"identities" section of the wikipedia article on matrix calculus for many more examples.
| [1] | A few words on notation: by default, a vector v is a column vector. To get its row version, we transpose it. Moreover, in the vector derivative equations that follow I'm using denominator layout notation. This is not super-important though; as the Wikipedia article suggests, many mathematical papers and writings aren't consistent about this and it's perfectly possible to understand the derivations regardless. |
| [2] | Yes, this is exactly like computing a gradient of a multivariate function. |
| [3] | Take a minute to convince yourself that the dimensions of this equation work out and the result is a scalar. |