I was going through the Coursera "Machine Learning" course, and in the section on multivariate linear regression something caught my eye. Andrew Ng presented the Normal Equation as an analytical solution to the linear regression problem with a least-squares cost function. He mentioned that in some cases (such as for small feature sets) using it is more effective than applying gradient descent; unfortunately, he left its derivation out.
Here I want to show how the normal equation is derived.
First, some terminology. The following symbols are compatible with the machine learning course, not with the exposition of the normal equation on Wikipedia and other sites - semantically it's all the same, just the symbols are different.
Given the hypothesis function:
![\[h_{\theta}(x)=\theta_0x_0+\theta_1x_1+\cdots+\theta_nx_n\]](https://eli.thegreenplace.net/images/math/dd8fad9bf111e83d47252d51dd037a6c6c3136aa.png)
We'd like to minimize the least-squares cost:
![\[J(\theta_{0...n})=\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)})-y^{(i)})^2\]](https://eli.thegreenplace.net/images/math/c1abe0768f4deb31ed97f37d760236c94439a780.png)
Where 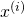 is the i-th sample (from a set of m samples) and
is the i-th sample (from a set of m samples) and
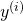 is the i-th expected result.
is the i-th expected result.
To proceed, we'll represent the problem in matrix notation; this is natural,
since we essentially have a system of linear equations here. The regression
coefficients 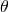 we're looking for are the vector:
we're looking for are the vector:
![\[\begin{pmatrix} \theta_0\\ \theta_1\\ ...\\ \theta_n \end{pmatrix}\in\mathbb{R}^{n+1}\]](https://eli.thegreenplace.net/images/math/b16fd3d2b3041f13cb70199837a7c02c756078c7.png)
Each of the m input samples is similarly a column vector with n+1 rows,
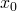 being 1 for convenience. So we can now rewrite the hypothesis
function as:
being 1 for convenience. So we can now rewrite the hypothesis
function as:
![\[h_{\theta}(x)=\theta^Tx\]](https://eli.thegreenplace.net/images/math/be661047c89f6a48c7bc563b81207949c251de6a.png)
When this is summed over all samples, we can dip further into matrix notation.
We'll define the "design matrix" X (uppercase X) as a matrix of m rows,
in which each row is the i-th sample (the vector ). With
this, we can rewrite the least-squares cost as following, replacing the explicit
sum by matrix multiplication:
![\[J(\theta)=\frac{1}{2m}(X\theta-y)^T(X\theta-y)\]](https://eli.thegreenplace.net/images/math/db5e3da78e25c18c8fc88f1291c1ac13a2645388.png)
Now, using some matrix transpose identities, we can simplify this a bit. I'll
throw the 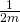 part away since we're going to compare a
derivative to zero anyway:
part away since we're going to compare a
derivative to zero anyway:
![\[J(\theta)=((X\theta)^T-y^T)(X\theta-y)\]](https://eli.thegreenplace.net/images/math/c1368de1a0634c3fbeb92d67f368f253943d089f.png)
![\[J(\theta)=(X\theta)^TX\theta-(X\theta)^Ty-y^T(X\theta)+y^Ty\]](https://eli.thegreenplace.net/images/math/e41fc822adccf1f865b02100f5671e265e7b30bc.png)
Note that 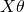 is a vector, and so is y. So when we multiply
one by another, it doesn't matter what the order is (as long as the dimensions
work out). So we can further simplify:
is a vector, and so is y. So when we multiply
one by another, it doesn't matter what the order is (as long as the dimensions
work out). So we can further simplify:
![\[J(\theta)=\theta^TX^TX\theta-2(X\theta)^Ty+y^Ty\]](https://eli.thegreenplace.net/images/math/2864b88546c007a79dc92271f5e01487ba608e43.png)
Recall that here is our unknown. To find where the above
function has a minimum, we will derive by and compare to 0.
Deriving by a vector may feel uncomfortable, but there's nothing to worry about.
Recall that here we only use matrix notation to conveniently represent a system
of linear formulae. So we derive by each component of the vector, and then
combine the resulting derivatives into a vector again. The result is:
![\[\frac{\partial J}{\partial \theta}=2X^TX\theta-2X^{T}y=0\]](https://eli.thegreenplace.net/images/math/9b142c00e031c9db7f575b0542e86261732a4689.png)
Or:
![\[X^TX\theta=X^{T}y\]](https://eli.thegreenplace.net/images/math/ab453f9f1f7bd4b1d646b9712fbe0b2fbe01740f.png)
Now, assuming that the matrix 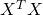 is invertible, we can multiply both
sides by
is invertible, we can multiply both
sides by 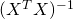 and get:
and get:
![\[\theta=(X^TX)^{-1}X^Ty\]](https://eli.thegreenplace.net/images/math/20baabd9d33dcd26003bc44c7d81ba39e1ad4caa.png)
Which is the normal equation.
[Update 27-May-2015: I've written another post that explains in more detail how these derivatives are computed.]