This is the seventh post in a series about writing REST servers in Go. Here is a list of posts in the series:
- Part 1 - standard library
- Part 2 - using a router package
- Part 3 - using a web framework
- Part 4 - using OpenAPI and Swagger
- Part 5 - middleware
- Part 6 - authentication
- Part 7 - GraphQL (this post)
In the previous parts of this series, we've focused on different approaches to develop a REST API for our simple task management application. In this part, we're going to take a much larger leap and look at how a similar API can be exposed with GraphQL instead of REST.
Although this post spends some time explaining the motivation for using GraphQL and compares GraphQL to REST, this is not its primary goal. There are many resources explaining these things, and I encourage you to google and read a few. The main goal of this post is to show an example of setting up a GraphQL server in Go. To make things simpler, it uses a very similar data model to the one in previous parts in the series (a simple backend API for managing a task list).
Motivation for GraphQL
GraphQL is an open-source data query and manipulation language for APIs, and a runtime for fulfilling queries with existing data.
Consider our task database as described in part 1; it's very simplistic, so to really motivate GraphQL we'll want to make it a bit more realistic. Let's add a sequences of attachments to each task; the Go model will now look like this:
type Attachment struct {
Name string `json:"Name"`
Date time.Time `json:"Date"`
Contents string `json:"Contents"`
}
type Task struct {
ID int `json:"Id"`
Text string `json:"Text"`
Tags []string `json:"Tags"`
Due time.Time `json:"Due"`
Attachments []*Attachment `json:"Attachments"`
}
Or, if you prefer a database schema diagram:
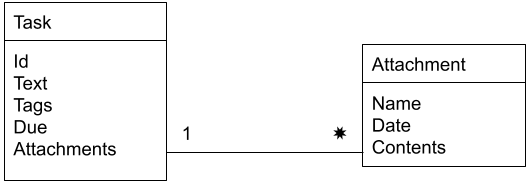
The 1 ---- * edge between the boxes implies a one-to-many relationship in relational database terms. Each task can have multiple attachments.
So far, our REST API has been:
POST /task/ : create a task, returns ID
GET /task/<taskid> : returns a single task by ID
GET /task/ : returns all tasks
DELETE /task/<taskid> : delete a task by ID
GET /tag/<tagname> : returns list of tasks with this tag
GET /due/<yy>/<mm>/<dd> : returns list of tasks due by this date
Specifically, note that many of these return a list of tasks. Suppose tasks have attachments now, as described above. Attachments can be fairly large. Now getting all the tasks for a tag with GET /tag/<tagname> may return a lot of data, even if the client only needs the names of the tasks. This isn't ideal, especially when the internet connection is slow or costs $$$ for bandwidth (think mobile clients, showing you the task list in a phone app). This is the problem of over-fetching simple REST APIs suffer from.
To solve the over-fetching problem, a common approach would be to return just the list of task IDs with GET /tag/<tagname>, instead of the tasks themselves. Then, having this list of IDs, the client can iterate over it and issue GET /task/<taskid> request for each. There could still be some over-fetching here, though, because we may not want the whole task, with attachments; so we may choose to only return attachment names (or IDs) and have yet another API endpoint to fetch these.
Now we have an opposite problem: under-fetching. Instead of issuing a single network request to get the information we need, we issue a whole bunch - potentially one for every task with a tag and then one for each attachment of this task. This approach has its own issues, e.g. higher latency.
How GraphQL addresses over-fetching and under-fetching
Let's spend a minute thinking how we could solve this issue. Obviously, we could design a specific REST endpoint to just give us the data we need. For example, GET /task-name-and-attachment-name-in-tag/<tagname> could return a list of task names, with a list of attachment names for each. No over-fetching, no under-fetching! This would work, and some REST APIs have specialized endpoints like this one; but the problem is obvious - this is hard to scale! Now suppose I want the same information, but not by tag; I want it by due date. Will I have to write a very similar endpoint, just for due date? It's possible, of course, but it should be obvious that as the API gets more complicated, there will be a lot of duplication.
Another alternative is to have a single endpoint to which I can submit a more complicated request. Let's call it a query. The query would express exactly what parts of the data I want; a bit like SQL.
Well, this is what GraphQL does. I'll get back to the SQL comparison later on, but for now let's see how GraphQL solves this. This is a GraphQL query that can be sent by the client:
query {
getTasksByTag(tag: "shopping") {
Text
Attachments{
Name
}
}
}
It will return a list of tasks, but for each task only the text of the task and the name of all its attachments will be returned. This is exactly the data we want, in a single response.
A task server in Go with GraphQL
I've taken the task server from the previous parts in the series, and rewrote it to use GraphQL. The data model was updated to include attachments, as described above. The full code for the server is available here.
There are several packages for GraphQL in Go; for this experiment, I went with gqlgen. It takes a GraphQL schema as input and generates a bunch of Go code to implement an HTTP server for serving queries in these schemas; the actual handlers (called resolvers in GraphQL parlance) are left as stubs for the developer to implement. gqlgen has a decent tutorial, so here I'll just focus on explaining how my server works.
Here's the GraphQL schema for our tasks backend [1]:
type Query {
getAllTasks: [Task]
getTask(id: ID!): Task
getTasksByTag(tag: String!): [Task]
getTasksByDue(due: Time!): [Task]
}
type Mutation {
createTask(input: NewTask!): Task!
deleteTask(id: ID!): Boolean
deleteAllTasks: Boolean
}
scalar Time
type Attachment {
Name: String!
Date: Time!
Contents: String!
}
type Task {
Id: ID!
Text: String!
Tags: [String!]
Due: Time!
Attachments: [Attachment!]
}
input NewAttachment {
Name: String!
Date: Time!
Contents: String!
}
input NewTask {
Text: String!
Tags: [String!]
Due: Time!
Attachments: [NewAttachment!]
}
Several things to note here:
- The Query and Mutation types are special in GraphQL - they define the actual API. The other types are interesting too - GraphQL is strongly typed! This is nice, as it makes validation of input a better defined task (the JSON typically used in REST is much less strongly typed).
- Even though APIs in the Query type appear to return [Task], which is a list of tasks, there is no over-fetching here. As the sample query in the previous section demonstrates, GraphQL lets clients specify exactly the fields they want from the returned values in their query, and only these fields get tranferred over the wire. See my sample query earlier for a realistic example.
- GraphQL doesn't have a build-in type for times and dates, but one can write extensions; here I'm using the scalar Time extension which is built into gqlgen - it maps it to Go's time.Time.
Finally, it's hard to not notice the NewTask and NewAttachment types that duplicate Task and Attachment. What's up with that? The answer here is rather complicated. GraphQL types can represent graphs, in the sense that one task can have multiple attachments, but in theory each attachment can belong to multiple tasks. This could be the source of the "graph" in GraphQL's name (I'll be happy to know if I'm wrong about this!), and it's very different from how we design relational databases.
Such graph data could be tricky to construct in a parameter; if it's mutually recursive, how do you do it? So GraphQL opted for a strict separation - types usable as inputs need to be clearly marked as such, and can only be trees, not graphs. Therefore, while we theoretically could have reused Task for input parameters (since it's not a graph), GraphQL forbids this and insists on a new type.
The steps I followed with my project were:
- go run github.com/99designs/gqlgen init
- Write my GraphQL schema as shown above
- go run github.com/99designs/gqlgen generate
- Update the generated code to implement my resolvers
- Run the generated server.go
For the resolvers, gqlgen emits an empty struct type called Resolver, on which the handler methods are defined. This struct should be updated by the application to include any shared context information needed for all resolvers. For the task application, we just need the task store:
type Resolver struct {
Store *taskstore.TaskStore
}
gqlgen also generates stub handler methods which we should fill in. For most resolvers, this is trivial; for example:
func (r *queryResolver) GetAllTasks(ctx context.Context) ([]*model.Task, error) {
return r.Store.GetAllTasks(), nil
}
Note that our resolver returns the list of tasks in their entirety; the field selection (or "no over-fetching") feature of GraphQL is implemented by the code gqlgen generates for us. As far as I could find, there's not way to know in the resolver which fieds the query is asking for, so we always have to fetch everything from the DB [2]. This may be a limitation of gqlgen, or it just may be the way all GraphQL servers work - I'm not sure.
Finally, gqlgen generates a main function for us in server.go, which we can tweak:
func main() {
port := os.Getenv("PORT")
if port == "" {
port = defaultPort
}
resolver := &graph.Resolver{
Store: taskstore.New(),
}
srv := handler.NewDefaultServer(generated.NewExecutableSchema(generated.Config{Resolvers: resolver}))
http.Handle("/", playground.Handler("GraphQL playground", "/query"))
http.Handle("/query", srv)
log.Printf("connect to http://localhost:%s/ for GraphQL playground", port)
log.Fatal(http.ListenAndServe(":"+port, nil))
}
Here handler.NewDefaultServer is the GraphQL server, and it's registered on the /query path. We could add more paths here - for example, we could even mix REST with GraphQL.
Playground - interacting with a GraphQL server
One of the coolest features of GraphQL is the playground which makes it very pleasant and easy to experiment with a server right from the browser. In the server code above, you'll note the playground.Handler registered to serve on the root path. It serves a single-page application called graphql-playground; here's how it looks:
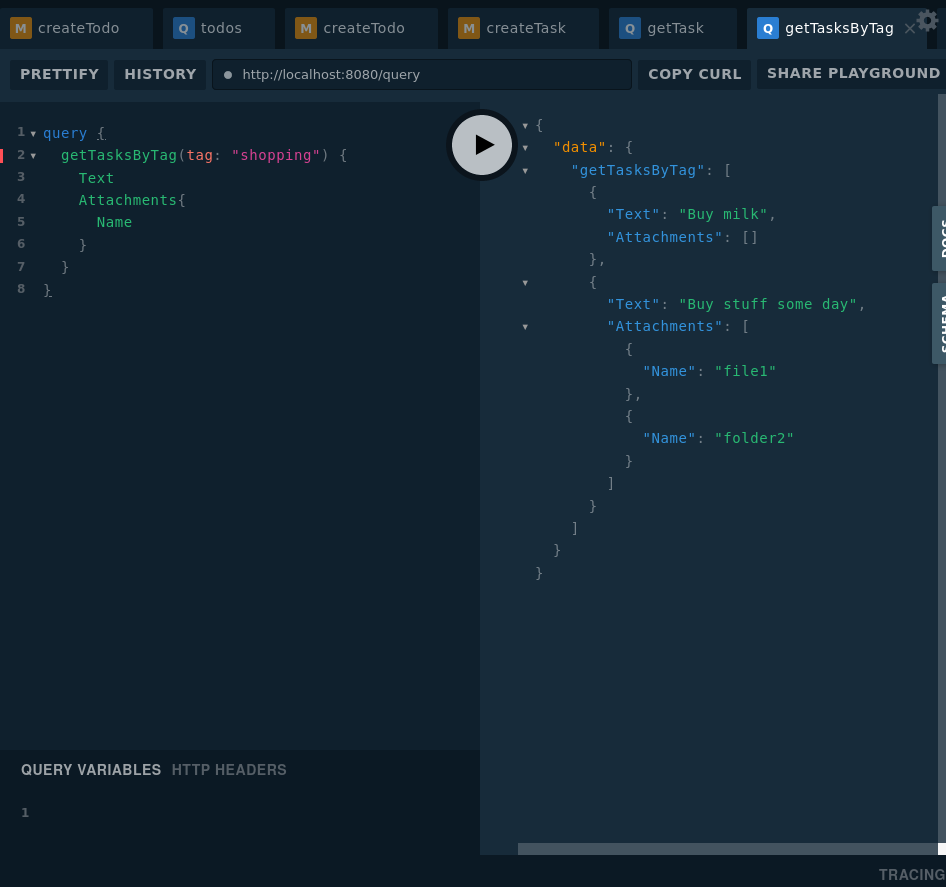
As you can see, I typed in the query mentioned earlier and when it runs, the data returned by the server can be seen in the right pane. The playground includes syntax highlighting, completion, multiple tabs and even allows you to translate queries into curl invocations if you need to save them to testing scripts.
GraphQL vs. REST
At the basic level, GraphQL has some clear advantages vs. REST, particularly in the area of efficiency where over- or under-fetching can cause REST APIs to be suboptimal. That said, this flexibility in GraphQL comes at a cost - it becomes very easy to submit arbitrarily complex GraphQL queries and thus cause DoS attacks to the server; obviously, best practices are evolving to help GraphQL server developers avoid these pitfalls.
GraphQL is an emerging technology, and a lot of interesting tooling is evolving along with it - like the playground shown above. However, REST has been around for much longer and is difficult to compete with w.r.t. tooling and interoperability. Pretty much any server has a REST API today, and much tooling has been built for monitoring, logging, profiling and other introspection of REST APIs. REST is also very simple - just paths to access over HTTP, and can often be exercised with simple curl invocations or in the browser. GraphQL is more involved as the query has to be placed into the body of a POST request.
The simplicity of REST has a deeper implication; in a typical web backend, REST queries will be serviced by (often non-trivial) SQL queries sent to a DB. GraphQL adds its own query language, which is a little bit like SQL in some ways but also very different in other ways, because the graph model it relies on is not really relational. So GraphQL, in my experience, makes you keep more state in your head - the state of the GraphQL query and how it maps to the underlying relational DB. Emerging projects like Dgraph (a native GraphQL DB with a graph backend) and PostGraphile (an automatic mapper bewteen GraphQL and PostgreSQL) are interesting players worth watching in this field.
Another point worth mentioning is caching; REST plays well with HTTP caching, since much of it relies on idempotent GET requests. GraphQL is trickier in this regard, since it doesn't distinguish between idempotent data queries and mutations on the HTTP level.
At the end of the day, engineers are either constrained by the systems they have to interact with, or (in rare, lucky cases) have the ability to choose the technology for a new project. In the latter case, pick the right tool for the job. It's good to have more options!
| [1] | GraphQL schemas are written in a language that's codified by a spec. |
| [2] | In SQL parlance, we're always asked to do a select * from ... rather than a select on specific fields. Once our resolver returns this data to the GraphQL engine, it will only send the selected fields to the client. |