The chain rule of derivatives is, in my opinion, the most important formula in differential calculus. In this post I want to explain how the chain rule works for single-variable and multivariate functions, with some interesting examples along the way.
Preliminaries: composition of functions and differentiability
We denote a function f that maps from the domain X to the codomain Y as
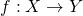 . With this f and given
. With this f and given 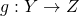 , we
can define
, we
can define 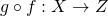 as the composition of g and f.
It's defined for
as the composition of g and f.
It's defined for 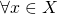 as:
as:
![\[(g \circ f)(x)=g(f(x))\]](https://eli.thegreenplace.net/images/math/8b9c8e67c9d2ec7fd3eefce043f380512f1230d3.png)
In calculus we are usually concerned with the real number domain of some
dimensionality. In the single-variable case, we can think of 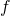 and
and
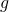 as two regular real-valued functions:
as two regular real-valued functions:
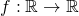 and
and
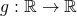 .
.
As an example, say 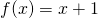 and
and 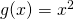 . Then:
. Then:
![\[(g \circ f)(x)=g(f(x))=g(x+1)=(x+1)^2\]](https://eli.thegreenplace.net/images/math/f80635cd447f9f82452529c9289d16811394ea6c.png)
We can compose the functions the other way around as well:
![\[(f \circ g)(x)=f(g(x))=f(x^2)=x^2+1\]](https://eli.thegreenplace.net/images/math/13c07f9e990c72b1edaf651fccec5c4ad7c0f155.png)
Obviously, we shouldn't expect composition to be commutative.
It is, however, associative. 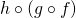 and
and
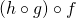 are equivalent, and both end up being
are equivalent, and both end up being
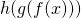 for .
for .
To better handle compositions in one's head it sometimes helps to denote the
independent variable of the outer function (g in our case) by a different
letter (such as 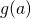 ). For simple cases it doesn't matter, but I'll
be using this technique occasionally throughout the article. The important thing
to remember here is that the name of the independent variable is completely
arbitrary, and we should always be able to replace it by another name throughout
the formula without any semantic change.
). For simple cases it doesn't matter, but I'll
be using this technique occasionally throughout the article. The important thing
to remember here is that the name of the independent variable is completely
arbitrary, and we should always be able to replace it by another name throughout
the formula without any semantic change.
The other preliminary I want to mention is differentiability. The function f
is differentiable at some point 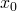 if the following limit exists:
if the following limit exists:
![\[\lim_{h \to 0}\frac{f(x_0+h)-f(x_0)}{h}\]](https://eli.thegreenplace.net/images/math/34b3ce83a20775cf99b8d204d2b845dfde5727cc.png)
This limit is then the derivative of f at the point , or
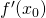 . Another way to express this is
. Another way to express this is 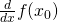 .
Note that can be any arbitrary point on the real line. I sometimes
say something like "f is differentiable at
.
Note that can be any arbitrary point on the real line. I sometimes
say something like "f is differentiable at 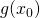 ". Here too,
is just a real value that happens to be the value of the function
g at .
". Here too,
is just a real value that happens to be the value of the function
g at .
The single-variable chain rule
The chain rule for single-variable functions states: if g is differentiable at
and f is differentiable at , then 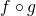 is differentiable at and its derivative is:
is differentiable at and its derivative is:
![\[(f \circ g)'(x_0)={f}'(g(x_0)){g}'(x_0)\]](https://eli.thegreenplace.net/images/math/77fb8b77b35d687c20379179b0178ebdd9b2cee1.png)
The proof of the chain rule is a bit tricky - I left it for the appendix. However, we can get a better feel for it using some intuition and a couple of examples.
First, the intuituion. By definition:
![\[{g}'(x_0)=\lim_{h \to 0}\frac{g(x_0+h)-g(x_0)}{h}\]](https://eli.thegreenplace.net/images/math/cdc3e4a3bced3a7527a15cd76a688d5cc1c06aab.png)
Multiplying both sides by h we get [1]:
![\[{g}'(x_0)h=\lim_{h \to 0}g(x_0+h)-g(x_0)\]](https://eli.thegreenplace.net/images/math/daf52cabed3806986d4c8c29dd60e4ce4fa9247d.png)
Therefore we can say that when changes by some very small amount,
changes by 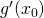 times that small amount.
times that small amount.
Similarly 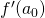 is the amount of change in the value of f for some
very small change from
is the amount of change in the value of f for some
very small change from 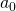 . However, since in our case we compose
, we can say that
. However, since in our case we compose
, we can say that 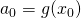 , evaluating
, evaluating
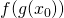 . Suppose we shift by a small amount h. This
causes to shift by
. Suppose we shift by a small amount h. This
causes to shift by 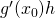 . So the input
of f shifted by - this is still a small amount! Therefore,
the total change in the value of f should be
. So the input
of f shifted by - this is still a small amount! Therefore,
the total change in the value of f should be 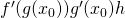 [2].
[2].
Now, a couple of simple examples. Let's take the function 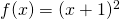 .
The idea is to think of this function as a composition of simpler functions.
In this case, one option is:
.
The idea is to think of this function as a composition of simpler functions.
In this case, one option is: 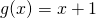 and then
and then 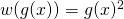 ,
so the original f is now the composition
,
so the original f is now the composition 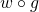 .
.
The derivative of this composition is 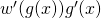 , or
, or
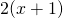 since
since 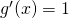 . Note that w is differentiable at any
point, so this derivative always exists.
. Note that w is differentiable at any
point, so this derivative always exists.
Another example will use a longer chain of composition. Let's differentiate
![f(x)=sin[(x+1)^2]](https://eli.thegreenplace.net/images/math/3e3a23e0dd5d4ee105bcca545bddb058917e2c9c.png) . This is a composition of three functions:
. This is a composition of three functions:
![\[\begin{align*} g(x)&=x+1\\ w(x)&=x^2\\ v(x)&=sin(x) \end{align*}\]](https://eli.thegreenplace.net/images/math/6981c04536025d8e43d07bf9b067252c2028feab.png)
Function composition is associative, so f can be expressed as either
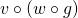 or
or 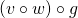 . Since we already
know what the derivative of is, let's use the former:
. Since we already
know what the derivative of is, let's use the former:
 \end{align*}\]](https://eli.thegreenplace.net/images/math/f63f9a07295583911873238c3ee6e84e8c3722ca.png)
The chain rule as a computational procedure
As the last example demonstrates, the chain rule can be applied multiple times in a single derivation. This makes the chain rule a powerful tool for computing derivatives of very complex functions, which can be broken up into compositions of simpler functions. I like to draw a parallel between this process and programming; a function in a programming language can be seen as a computational procedure - we have a set of input parameters and we produce outputs. On the way, several transformations happen that can be expressed mathematically. These transformations are composed, so their derivatives can be computed naturally with the chain rule.
This may be somewhat abstract, so let's use another example. We'll compute the derivative of the Sigmoid function - a very important function in machine learning:
![\[S(x)=\frac{1}{1+e^{-x}}\]](https://eli.thegreenplace.net/images/math/9a39d0495ce32da5840b76adaf508a0349394c49.png)
To make the equivalence between functions and computational procedures clearer, let's think how we'd compute S in Python:
def sigmoid(x):
return 1 / (1 + math.exp(-x))
This doesn't look much different, but that's just because Python is a high level language with arbitrarily nested expressions. Its VM (or the CPU in general) would execute this computation step by step. Let's break it up to be clearer, assuming we can only apply a single operation at every step:
def sigmoid(x):
f = -x
g = math.exp(f)
w = 1 + g
v = 1 / w
return v
I hope you're starting to see the resemblance to our chain rule examples at this point. Sacrificing some rigor in the notation for the sake of expressiveness, we can write:
![\[S'=v'(w)w'(g)g'(f)f'(x)\]](https://eli.thegreenplace.net/images/math/b3029d842b915e7bf0ea1aa91372ab071dd8b80e.png)
This is the chain rule applied to 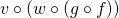 . Solving
this is easy because every single derivative in the chain above is trivial:
. Solving
this is easy because every single derivative in the chain above is trivial:
![\[\begin{align*} S'&=v'(w)w'(g)g'(f)(-1)\\ &=v'(w)w'(g)e^{-x}(-1)\\ &=v'(w)(1)e^{-x}(-1)\\ &=\frac{-1}{(1+e^{-x})^2}e^{-x}(-1)\\ &=\frac{e^{-x}}{(1+e^{-x})^2} \end{align*}\]](https://eli.thegreenplace.net/images/math/b987461a2551ca622908f40f791519f3afe3b452.png)
Now you may be thinking:
- Every function computable by a program can be broken down to trivial steps like our sigmoid above.
- Using the chain rule, we can easily find the derivative of such a sequence of steps... therefore:
- We can easily find the derivative of any function computable by a program!!
An you'll be right. This is precisely the basis for the technique known as automatic differentiation, which is widely used in scienctific computing. The most notable use of automatic differentiation in recent times is the backpropagation algorithm - an essential backbone of modern machine learning. I personally find automatic differentiation fascinating, and will write a more dedicated article about it in the future.
Update (2025-01-13): Check out this post on the subject.
Multivariate chain rule - general formulation
So far this article has been looking at functions with a single input and
output: 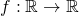 . In the most general case of
multi-variate calculus, we're dealing with functions that map from n
dimensions to m dimensions:
. In the most general case of
multi-variate calculus, we're dealing with functions that map from n
dimensions to m dimensions: 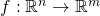 .
Because every one of the m outputs of f can be considered a separate
function dependent on n variables, it's very natural to deal with such math
using vectors and matrices.
.
Because every one of the m outputs of f can be considered a separate
function dependent on n variables, it's very natural to deal with such math
using vectors and matrices.
First let's define some notation. We'll consider the outputs of f to be
numbered from 1 to m as 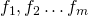 . For each such
. For each such 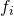 we can compute its partial derivative by any of the n inputs as:
we can compute its partial derivative by any of the n inputs as:
![\[D_j f_i(a)=\frac{\partial f_i}{\partial a_j}(a)\]](https://eli.thegreenplace.net/images/math/30881b5a92e45259714ba01c7a12fbf8f6c56109.png)
Where j goes from 1 to n and a is a vector with n components. If f is differentiable at a [3] then the derivative of f at a is the Jacobian matrix:
![\[Df(a)=\begin{bmatrix} D_1 f_1(a) & \cdots & D_n f_1(a) \\ \vdots & & \vdots \\ D_1 f_m(a) & \cdots & D_n f_m(a) \\ \end{bmatrix}\]](https://eli.thegreenplace.net/images/math/ab09367d48e9ef4d8bc2314a60313dec700193af.png)
The multivariate chain rule states: given 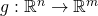 and
and 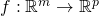 and a point
and a point 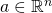 ,
if g is differentiable at a and f is differentiable at then
the composition is differentiable at a and its derivative
is:
,
if g is differentiable at a and f is differentiable at then
the composition is differentiable at a and its derivative
is:
![\[D(f \circ g)(a)=Df(g(a)) \cdot Dg(a)\]](https://eli.thegreenplace.net/images/math/00bdefa904bd34df2dfb50cc385e6497c4e5096e.png)
Which is the matrix multiplication of 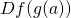 and
and 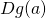 [4].
Intuitively, the multivariate chain rule mirrors the single-variable one (and as
we'll soon see, the latter is just a special case of the former) with
derivatives replaced by derivative matrices. From linear algebra, we represent
linear transformations by matrices, and the composition of two linear transformations
is the product of their matrices. Therefore, since derivative matrices - like
derivatives in one dimension - are a linear approximation to the function, the
chain rule makes sense. This is a really nice connection between linear algebra
and calculus, though a full proof of the multivariate rule is very technical and
outside the scope of this article.
[4].
Intuitively, the multivariate chain rule mirrors the single-variable one (and as
we'll soon see, the latter is just a special case of the former) with
derivatives replaced by derivative matrices. From linear algebra, we represent
linear transformations by matrices, and the composition of two linear transformations
is the product of their matrices. Therefore, since derivative matrices - like
derivatives in one dimension - are a linear approximation to the function, the
chain rule makes sense. This is a really nice connection between linear algebra
and calculus, though a full proof of the multivariate rule is very technical and
outside the scope of this article.
Multivariate chain rule - examples
Since the chain rule deals with compositions of functions, it's natural to
present examples from the world of parametric curves and surfaces. For example,
suppose we define 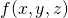 as a scalar function
as a scalar function
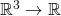 giving the temperature
at some point in 3D. Now imagine that we're moving through this 3D space on
a curve defined by a function
giving the temperature
at some point in 3D. Now imagine that we're moving through this 3D space on
a curve defined by a function 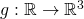 which takes
time t and gives the coordinates
which takes
time t and gives the coordinates 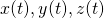 at that time. We want
to compute how the temperature changes as a function of time t - how do we do
that? Recall that the temprerature is not a direct function of time, but rather
is a function of location, while location is a function of time. Therefore,
we'll want to compose . Here's a concrete example:
at that time. We want
to compute how the temperature changes as a function of time t - how do we do
that? Recall that the temprerature is not a direct function of time, but rather
is a function of location, while location is a function of time. Therefore,
we'll want to compose . Here's a concrete example:
![\[g(t)=\begin{pmatrix} t\\ t^2\\ t^3 \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/cdaff94ebfb318ec24f472be470497e28a091c42.png)
And:
![\[f\begin{pmatrix} x \\ y \\ z \end{pmatrix}=x^2+xyz+5y\]](https://eli.thegreenplace.net/images/math/0a2fc40b06886d3b54628680192d71a3186d9fc7.png)
If we reformulate x, y and z as functions of t:
Composing , we get:
![\[(f \circ g)(t)=f(g(t))=f(t,t^2,t^3)=t^2+t^6+5t^2=6t^2+t^6\]](https://eli.thegreenplace.net/images/math/63ad25f62a0e93b1f8175a627aac0a29a88a3cca.png)
Since this is a simple function, we can find its derivative directly:
![\[(f \circ g)'(t)=12t+6t^5\]](https://eli.thegreenplace.net/images/math/d1025880b042d304efe08de37eeafde5a8d9231c.png)
Now let's repeat this exercise using the multivariate chain rule. To compute
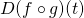 we need
we need 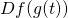 and
and 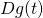 . Let's start
with .
. Let's start
with . 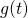 maps
maps 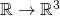 ,
so its Jacobian is a 3-by-1 matrix, or column vector:
,
so its Jacobian is a 3-by-1 matrix, or column vector:
![\[Dg(t)=\begin{bmatrix} 1 \\ 2t \\ 3t^2 \end{bmatrix}\]](https://eli.thegreenplace.net/images/math/492d3e9013352e0cd44e3c5721cd0535174fb318.png)
To compute let's first find 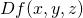 . Since
maps , its Jacobian is a
1-by-3 matrix, or row vector:
. Since
maps , its Jacobian is a
1-by-3 matrix, or row vector:
![\[Df(x,y,z)=\begin{bmatrix} 2x+yz & xz+5 & xy \end{bmatrix}\]](https://eli.thegreenplace.net/images/math/e8d650cac68d341d2c99c2641be3d238e516e51c.png)
To apply the chain rule, we need :
![\[Df(g(t))=\begin{bmatrix} 2t+t^5 & t^4+5 & t^3 \end{bmatrix}\]](https://eli.thegreenplace.net/images/math/b061977c12dcc918a96473939f6dc01eb7ea7847.png)
Finally, multiplying by , we get:
![\[\begin{align*} D(f \circ g)(t)=Df(g(t)) \cdot Dg(t)&=\begin{bmatrix} 2t+t^5 & t^4+5 & t^3 \end{bmatrix} \cdot \begin{bmatrix} 1 \\ 2t \\ 3t^2 \end{bmatrix}\\ &=2t+t^5+2t^6+10t+3t^5\\ &=12t+6t^5 \end{align*}\]](https://eli.thegreenplace.net/images/math/9c5a5fc3e8024f6d1f2364ad5d0433bb530d4987.png)
Another interesting way to interpret this result for the case where
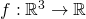 and
is to recall that
the directional derivative of f in the direction of some vector
and
is to recall that
the directional derivative of f in the direction of some vector 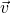 is:
is:
![\[D_{\vec{v}}f=(\nabla f) \cdot \vec{v}\]](https://eli.thegreenplace.net/images/math/49933775272512c4c8686d9f9692c8ea01e1c97d.png)
In our case 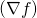 is the Jacobian of f (because of its
dimensionality). So if we take to be the vector ,
and evaluate the gradient at we get [5]:
is the Jacobian of f (because of its
dimensionality). So if we take to be the vector ,
and evaluate the gradient at we get [5]:
![\[D_{\vec{Dg(t)}}f(t)=(\nabla f(g(t))) \cdot Dg(t)\]](https://eli.thegreenplace.net/images/math/dc8e045fe902682ada36e08fa0099f95632b7ced.png)
This gives us some additional intuition for the temperature change question. The
change in temperature as a function of time is the directional derivative of f
in the direction of the change in location ().
For additional examples of applying the chain rule, see my post about softmax.
Tricks with the multivariate chain rule - derivative of products
Earlier in the article we've seen how the chain rule helps find derivatives of
complicated functions by decomposing them into simpler functions. The
multivariate chain rule allows even more of that, as the following example
demonstrates. Suppose 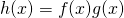 . Then, the well-known product rule of derivatives states that:
. Then, the well-known product rule of derivatives states that:
![\[h'(x)=f'(x)g(x)+f(x)g'(x)\]](https://eli.thegreenplace.net/images/math/6c77a942dbee351e8229ce7771680b6a2f55c4aa.png)
Proving this from first principles (the definition of the derivative as a limit) isn't hard, but I want to show how it stems very easily from the multivariate chain rule.
Let's begin by re-formulating 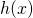 as a composition of two functions.
The first takes a vector
as a composition of two functions.
The first takes a vector 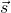 in
in 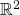 and maps it to
and maps it to
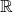 by computing the product of its two components:
by computing the product of its two components:
![\[p(\vec{s})=s_1 s_2\]](https://eli.thegreenplace.net/images/math/955d480267a38ec452bcdf2774dadc7652a757fa.png)
The second is a vector-valued function that maps a number
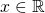 to :
to :
![\[s(x)=\begin{pmatrix} f(x)\\ g(x) \end{pmatrix}\]](https://eli.thegreenplace.net/images/math/f5c473fb1fb5ee47e59414a91dc484e182bc6210.png)
We can compose 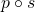 , producing a function that takes
a scalar an returns a scalar:
, producing a function that takes
a scalar an returns a scalar: 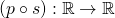 .
We get:
.
We get:
![\[h(x)=(p \circ s)(x) = f(x)g(x)\]](https://eli.thegreenplace.net/images/math/3cbae5f44d32653bd6bbc66e6ee8bb5e1a4dfe40.png)
Since we're composing two multivariate functions, we can apply the multivariate chain rule here:
![\[\begin{align*} D(p \circ s) &= Dp(s(x)) \cdot Ds(x)\\ &=\begin{bmatrix} \frac{\partial p}{\partial s_1}(x) & \frac{\partial p}{\partial s_2}(x) \end{bmatrix}\cdot \begin{bmatrix} {s_1}'(x)\\ {s_2}'(x) \end{bmatrix}\\ &=\begin{bmatrix} s_2(x) & s_1(x) \end{bmatrix} \cdot \begin{bmatrix} {s_1}'(x)\\ {s_2}'(x) \end{bmatrix}\\ &={s_1}'(x)s_2(x)+{s_2}'(x)s_1(x) \end{align*}\]](https://eli.thegreenplace.net/images/math/ee8bd27a8257039f72c8751eb78626521f12a5fa.png)
Since 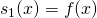 and
and 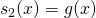 , this is exactly the product
rule.
, this is exactly the product
rule.
Connecting the single-variable and multivariate chain rules
Given function 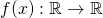 , its Jacobian matrix
has a single entry:
, its Jacobian matrix
has a single entry:
![\[Df(a)=\begin{bmatrix}D_{x}f(a)\end{bmatrix}= \begin{bmatrix}\frac{df}{dx}(a)\end{bmatrix}\]](https://eli.thegreenplace.net/images/math/cc95d53415b32e6610c1a45bededb4fb584f0c64.png)
Therefore, given two functions mapping 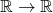 , the
derivative of their composition using the multivariate chain rule is:
, the
derivative of their composition using the multivariate chain rule is:
![\[D(f \circ g)(a)=Df(g(a))\cdot Dg(a)=f'(g(a))g'(a)\]](https://eli.thegreenplace.net/images/math/98e554584c9d2d967b9a6759a64126093ef704ce.png)
Which is precisely the single-variable chain rule. This results from matrix multiplication between two 1x1 matrices, which ends up being just the product of their single entries.
Appendix: proving the single-variable chain rule
It turns out that many online resources (including Khan Academy) provide a flawed proof for the chain rule. It's flawed due to a careless division by a quantity that may be zero. This flaw can be corrected by making the proof somewhat more complicated; I won't take that road here - for details see Spivak's Calculus. Instead, I'll present a simpler proof inspired by the one I found at Casey Douglas's site.
We want to prove that:
![\[(f \circ g)'(x)={f}'(g(x)){g}'(x)\]](https://eli.thegreenplace.net/images/math/29f4194c9af3777ae55a15dad972a145eb7797be.png)
Note that previously we defined derivatives at some concrete point .
Here for the sake of brevity I'll just use 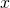 as an arbitrary point,
assuming the derivative exists.
as an arbitrary point,
assuming the derivative exists.
Let's start with the definition of 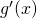 :
:
![\[{g}'(x)=\lim_{h \to 0}\frac{g(x+h)-g(x)}{h}\]](https://eli.thegreenplace.net/images/math/c19f7ddc43c3046489d7e012c3f213403edf7e8a.png)
We can reorder it as follows:
![\[\lim_{h \to 0}\left [ \frac{g(x+h)-g(x)}{h} - g'(x) \right ] = 0\]](https://eli.thegreenplace.net/images/math/74a651394036af8aeaba69650dba26ccb4f90ae7.png)
Let's give the part in the brackets the name 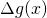 .
.
Similarly, if the function f is differentiable at the point 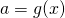 ,
we have:
,
we have:
![\[f'(a)=\lim_{k \to 0}\frac{f(a+k)-f(a)}{k}\]](https://eli.thegreenplace.net/images/math/59daea2a46cd244229625131297a773820501571.png)
We reorder:
![\[\lim_{k \to 0}\left [ \frac{f(a+k)-f(a)}{k} - f'(a) \right ] = 0\]](https://eli.thegreenplace.net/images/math/4600064fad365f360bd73063324a935a8b73266f.png)
And call the part in the brackets 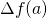 . The choice of the
variable used to go to zero: k instead of h is arbitrary and is useful to
simplify the discussion that follows.
. The choice of the
variable used to go to zero: k instead of h is arbitrary and is useful to
simplify the discussion that follows.
Let's reorder the definition of a bit:
![\[g(x+h)=g(x)+[g'(x)+\Delta g(x)]h\]](https://eli.thegreenplace.net/images/math/59e0263f8a2ebfc0fac9a2b51f42c651b359fe31.png)
We can apply f to both sides:
![\[\begin{equation} f(g(x+h))=f(g(x)+[g'(x)+\Delta g(x)]h) \tag{1} \end{equation}\]](https://eli.thegreenplace.net/images/math/3b82da9d6cad509490e687b9e86093791545ea81.png)
By reordering the definition of we get:
![\[\begin{equation} f(a+k)=f(a)+[f'(a)+\Delta f(a)]k \tag{2} \end{equation}\]](https://eli.thegreenplace.net/images/math/88c5b43f3ba89da3853be9342381aa8dd60e024f.png)
Now taking the right-hand side of (1), we can look at it as 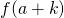 since and we can define
since and we can define ![k=[g'(x)+\Delta g(x)]h](https://eli.thegreenplace.net/images/math/ed49f313283b8f266ffd1e9b4194c36f456a950d.png) . We still
have k going to zero when h goes to zero. Assigning these a and k into
(2) we get:
. We still
have k going to zero when h goes to zero. Assigning these a and k into
(2) we get:
![\[f(a+k)=f(g(x))+[f'(g(x))+\Delta f(g(x))][g'(x)+\Delta g(x)]h\]](https://eli.thegreenplace.net/images/math/275b3323c68b711b2458e4c748a887a368e32a40.png)
So, starting from (1) again, we have:
![\[\begin{align*} f(g(x+h))&=f(a+k) \\ &=f(g(x))+[f'(g(x))+\Delta f(g(x))][g'(x)+\Delta g(x)]h \end{align*}\]](https://eli.thegreenplace.net/images/math/82e67cf24d9eb3dad58e7d30cd89ba1c19e367fb.png)
Subtracting 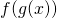 from both sides and dividing by h (which is legal,
since h is not zero, it's just very small) we get:
from both sides and dividing by h (which is legal,
since h is not zero, it's just very small) we get:
![\[\frac{f(g(x+h))-f(g(x))}{h}=[f'(g(x))+\Delta f(g(x))][g'(x)+\Delta g(x)]\]](https://eli.thegreenplace.net/images/math/bfdfef3d46b471aa5d6803c3c5a6b5e26ffe3b37.png)
Apply a limit to both sides:
![\[\lim_{h \to 0} \frac{f(g(x+h))-f(g(x))}{h}= \lim_{h \to 0} [f'(g(x))+\Delta f(g(x))][g'(x)+\Delta g(x)]\]](https://eli.thegreenplace.net/images/math/0f5c316fcc2877f78b8a739898a31120471dd401.png)
Now recall that both 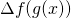 and go to 0 when
h goes to 0. Taking this into account, we get:
and go to 0 when
h goes to 0. Taking this into account, we get:
![\[\lim_{h \to 0} \frac{f(g(x+h))-f(g(x))}{h}= f'(g(x))g'(x)\]](https://eli.thegreenplace.net/images/math/3954d8d23c8fb53d4cd1732d19939d650ef830ae.png)
Q.E.D.
| [1] | Here, as in the rest of the post, I'm being careless with the usage of
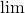 , sometimes leaving its existence to be implicit. In general,
wherever h appears in a formula we know there's a , sometimes leaving its existence to be implicit. In general,
wherever h appears in a formula we know there's a
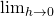 there, whether explicitly or not. there, whether explicitly or not. |
| [2] | An alternative way to think about it is: suppose the functions
f and g are linear: 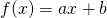 and and 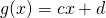 . Then
the chain rule is trivially true. But now recall what the derivative is.
The derivative at some point is the best linear approximation
for the function at that point. Therefore the chain rule is true for any
pair of differentiable functions - even when the functions are not
linear, we approximate their rate of change in an infinitisemal area
around with a linear function. . Then
the chain rule is trivially true. But now recall what the derivative is.
The derivative at some point is the best linear approximation
for the function at that point. Therefore the chain rule is true for any
pair of differentiable functions - even when the functions are not
linear, we approximate their rate of change in an infinitisemal area
around with a linear function. |
| [3] | The condition for f being differentiable at a is stronger than simply saying that all partial derivatives exist at a, but I won't spend more time on this subtlety here. |
| [4] | As an exercise, verify that the matrix dimensions of 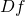 and
make this multiplication valid. and
make this multiplication valid. |
| [5] | It shouldn't be surprising we get here, since the definition of the directional derivative as the gradient was derived using the multivariate chain rule. |