This is the second part of the article. Make sure you read the first part before this one.
In this article I will explain how symbol tables are implemented in the CPython core [1]. The implementation itself is contained mainly in two files, the header Include/symtable.h and the C source file Python/symtable.c.
My strategy for understanding the implementation will follow Fred Brooks' advice from his book The Mythical Man-Month:
Show me your flowchart and conceal your tables, and I shall continue to be mystified. Show me your tables, and I won't usually need your flowchart; it'll be obvious.
A more modern translation would be: "The key to understanding a program is to understand its data structures. With that in hand, the algorithms usually become obvious."
This is especially true when the data structures of some module closely model the problem this module intends to solve, and the algorithms' job is to correctly create and use these data structures. Fortunately, this is exactly the case in CPython's implementation of symbol tables. Without further ado, let's delve in.
Symbol table entries
The key data structure to study is the symbol table entry, named PySTEntryObject [2]:
typedef struct _symtable_entry {
PyObject_HEAD
PyObject *ste_id;
PyObject *ste_symbols;
PyObject *ste_name;
PyObject *ste_varnames;
PyObject *ste_children;
_Py_block_ty ste_type;
int ste_unoptimized;
int ste_nested;
unsigned ste_free : 1;
unsigned ste_child_free : 1;
unsigned ste_generator : 1;
unsigned ste_varargs : 1;
unsigned ste_varkeywords : 1;
unsigned ste_returns_value : 1;
int ste_lineno;
int ste_opt_lineno;
int ste_tmpname;
struct symtable *ste_table;
} PySTEntryObject;
Before I explain what each field in the structure means, some background is in order. An entry object is created for each block in the Python source code. A block is defined as:
[...] A piece of Python program text that is executed as a unit. The following are blocks: a module, a function body and a class definition. [...]
Therefore, if we have the following definition in our Python source:
def outer(aa):
def inner():
bb = 1
return aa + bb + cc
dd = aa + inner()
return dd
The definition of outer creates a block with its body. So does the definition of inner. In addition, the top-level module in which outer is defined is also a block. All these blocks are represented by symbol table entries.
In essence, each entry is a symbol table on its own, containing information on the symbols in the block it represents. These entries are linked together into hierarchies, to represent nested blocks.
Once again, the symtable module can be used to explore these entries. In the first part of the article I used it to show what CPython knows about the symbols, but here I want to show how entries work. Here's a function that uses symtable to show how entries nest:
def describe_symtable(st, recursive=True, indent=0):
def print_d(s, *args):
prefix = ' ' * indent
print(prefix + s, *args)
assert isinstance(st, symtable.SymbolTable)
print_d('Symtable: type=%s, id=%s, name=%s' % (
st.get_type(), st.get_id(), st.get_name()))
print_d(' nested:', st.is_nested())
print_d(' has children:', st.has_children())
print_d(' identifiers:', list(st.get_identifiers()))
if recursive:
for child_st in st.get_children():
describe_symtable(child_st, recursive, indent + 5)
When executed on the symbol table created from the Python code we saw earlier, it prints out:
Symtable: type=module, id=164192096, name=top
nested: False
has children: True
identifiers: ['outer']
Symtable: type=function, id=164192056, name=outer
nested: False
has children: True
identifiers: ['aa', 'dd', 'inner']
Symtable: type=function, id=164191736, name=inner
nested: True
has children: False
identifiers: ['aa', 'cc', 'bb']
Note how entries are nested. The top-level entry representing the module has the entry for outer as its child, which in turn has the entry for inner as its child.
With this understood, we can go over the fields of the PySTEntryObject struct and explain what each one means [3]. Note that I use the terms "block" and "entry" interchangeably.
- ste_id: a unique integer ID for the entry taken as the Python object ID of the AST node it was created from.
- ste_symbols: the actual symbol table of this entry, a Python dict object mapping symbol names to flags that describe them. See the describe_symbol function in part 1 of the article to understand what information is stored in the flags for each symbol. All the symbols that are used in the block (whether defined or only referenced) are mapped here.
- ste_name: block name (if applicable). For example, for the function outer, the name is outer. Used primarily for debugging and error reporting.
- ste_varnames: the name of the field (as well as the comment that follows it) is somewhat misleading [4]. It's actually a list of the parameters of the block. For example, for the outer function in the example it's a list with the single name aa.
- ste_children: list of child blocks (also PySTEntryObject objects). As we saw earlier, blocks are nested, modeling the nesting of scopes in the Python source.
- ste_type: a value of the enumeration type _Py_block_ty which has three possible values: FunctionBlock, ClassBlock, ModuleBlock for the three kinds of blocks supported by the symbol table.
- ste_unoptimized: this flag helps deal with some special blocks (top-level and those containing import *). It's safe to ignore it for our purposes.
- ste_nested: An integer flag: 1 if it's a function block nested in some other function block (like our inner function), 0 otherwise.
- Next come some other flags with information about the block: ste_free, ste_child_free, ste_generator, ste_varargs, ste_varkeywords and ste_returns_value. The comments after these flags describe them quite well.
- ste_lineno: number of the first line of the block in the Python source - taken directly from the AST.
- ste_opt_lineno: related to the ste_unoptimized flag. Again, we'll ignore it for now.
- ste_tmpname: used to generate temporary names of variables in comprehensions
- ste_table: link to the symtable object this entry is part of.
As I mentioned above, the entry is the key data structure in CPython's symbol table code. When the symbol table creation algorithm finishes running, we get a set of inter-linked (for nesting) entries which contain information about all the symbols defined and used in our code. These entries are used in later stages of the compiler to generate bytecode from the AST.
symtable
symtable is less important for the usage of symbol tables by the compiler, but it's essential for the initial construction of a symbol table from the AST.
The symbol table construction algorithm uses an instance of the symtable structure to keep its state as it walks the AST recursively and builds entries for the blocks it finds.
Here are the fields of symtable annotated:
- st_filename: name of the file being compiled - used for generating meaningful warnings and errors.
- st_cur: the current entry (PySTEntryObject) the construction algorithm is in. Think of it (together with st_stack) as the current state of the algorithm as it walks the AST nodes recursively to create new entries.
- st_top: top-level entry for the module. Serves as the entry-point for the second pass of the symbol table construction algorithm.
- st_blocks: a dict mapping entry IDs (ste_id) to entry objects. Can be used to find the entry for some AST node.
- st_stack: a list representing a stack of entries. Used when working on nested blocks.
- st_global: direct link to the ste_symbols dict of the top-level module entry (st_top). Useful for accessing global (module-level) definitions from anywhere.
- st_nblocks / st_future: these fields aren't being used anywhere in the source so we'll ignore them.
- st_private: the name of the current class. This field is used for "mangling" private variables in classes [5].
Midway recap: what we have so far
Now that we have the data structures covered, it should be much simpler to understand the code implementing symbol table construction. There's no need to memorize the meanings of all fields - they can serve as a reference when reading the rest of the article and/or the source code. But it's definitely recommended to go over them at least once to have a general sense of what each data structure contains.
Constructing the symbol table: algorithm outline
Once we have a clear notion in our head of what information the symbol table eventually contains, the algorithm for constructing it is quite obvious. In the following diagram I've sketched an outline:
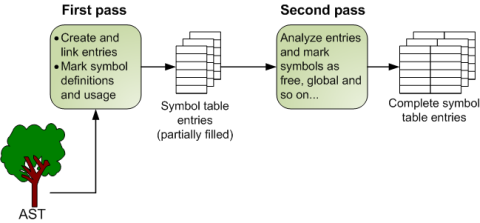
The algorithm is divided into two passes [6]. The first pass creates the basic structure of entries modeling the blocks in the source code and marks some of the simple information easily available directly in the AST - for example, which symbols are defined and referenced in each block.
The second pass walks the symbol table and infers the less obvious information about symbols: which symbols are free, which are implicitly global, etc.
Constructing the symbol table: first pass
The implementation of the first pass of the algorithm consumes a good chunk of the source-code of Python/symtable.c, but it's actually quite simple to understand, because the bulk of it exists to deal with the large variety of AST nodes Python generates.
First, let's take a look at how new blocks get created. When a new block-defining-statement (such as the top-level module or a function/class definition) is encountered, symtable_enter_block is called. It creates a new block and handles nesting by using st->st_stack [7], making sure st->st_cur always points to the currently processed block. The complementary function symtable_exit_block is called when a block has been processed. It uses st->st_stack to roll st->st_cur back to the enclosing block.
The next function that's important to understand is symtable_add_def. Its name could be clearer, though, since it's being called not only for symbol definitions but also for symbol uses (recall that the symbol table keeps track of which symbols are being used in which blocks). What it does is basically add a flag to the symbols dict (ste_symbols) of an entry that specifies the symbol's definition or use.
The rest of the code of the first pass is just a bunch of AST visiting functions that are implemented in a manner similar to other AST walkers in the CPython code base. There's a symtable_visit_<type> function for every major <type> of AST node the symbol table is interested in, along with a family of VISIT_* macros that help keep the code shorter.
I will pick a couple of examples to demonstrate the stuff explained earlier.
The most interesting would be handling function definitions in symtable_visit_stmt, under case FunctionDef_kind:
- First the function's name is added as a definition to the current block
- Next, default values, annotations and decorators are recursively visited.
- Since the function definition creates a new block, symtable_enter_block is called, only after which the actual function arguments and body get visited. Then, symtable_exit_block is called to get back to the parent block.
Another interesting example is the case Yield_kind code of symtable_visit_expr that handles yield statements. After visiting the yielded value (if any), the current block is marked as a generator. Since returning values from generators isn't allowed, the algorithm raises a syntax error if the block is also marked as returning a value [8].
The output of the first pass is a structurally complete symbol table, consisting of nested entries that model the blocks in the source code. At this stage the symbol table contains only partial information about symbols, however. Although it already maps all symbols defined and used in the code, and even flags special cases such as global symbols and generators, it still lacks some information, such as the distinction between free symbols that are defined in enclosing scopes and implicitly global symbols. This is the job of the second pass [9].
Constructing the symbol table: second pass
The second pass is actually documented not badly in the comments inside Python/symtable.c. However, these comments are scattered all over the place, so I'll try to provide a quick summary that should serve as a good starting point for reading the commented source. I will use a concrete example along with my explanation to aid understanding.
Here's our sample Python code once again:
def outer(aa):
def inner():
bb = 1
return aa + bb + cc
dd = aa + inner()
return dd
Let's focus on the symbols used in inner. After the first pass, the algorithm knows the following:
- bb is bound in inner
- aa is bound (as a parameter) in outer
- aa, bb, cc are used in inner
With this information, the algorithm should infer that aa is free and cc is global. For this, it runs another analysis, this time on the entries, pushing information from parent blocks into child blocks and back up again.
For example, when it analyzes inner, the second pass takes along a set of all variables bound in inner's parent (enclosing) scopes - aa and dd. In the analysis of inner, seeing that aa is used but not defined in inner but is defined in an enclosing scope, it can go on and mark aa as a free variable in the ste_symbols dict for inner's entry. Similarly, seeing that cc is not defined in any enclosing scope, it marks it global.
The information has to travel back up as well. An implementation detail of CPython which we won't get into in this article is "cells" which are used to implement free variables. For the purposes of the symbol table, all we need to know is that the symbol table is required to mark which variables serve as cells in an enclosing scopes for free variables in child scopes. So the algorithm should mark aa as a cell variable in outer. For this, it should first analyze inner and find out it's free there.
The most important function of the second pass is analyze_block - it is being called over and over again for each block in the symbol table. The arguments of analyze_block are:
- ste: The symbol table entry for the block to analyze
- bound: a set of all variables bound in enclosing scopes
- global: a set of all variables declared global in enclosing scopes
- free: output from the function - the set of all free variables in this entry and its enclosed scopes
Using a couple of auxiliary functions, analyze_block calls itself recursively on the child blocks of the given block, passing around and gathering the required information. Apart from creating the free set for the enclosing scope, analyze_block modifies ste as it finds new information about symbols in it.
Special thanks to Nick Coghlan for reviewing this article.

| [1] | The specific version I'm describing is a relatively up-to-date snapshot of the py3k branch, in other words the "cutting edge" of CPython. |
| [2] | The struct declaration in Include/symtable.h has short comments after each field. I've removed those intentionally. |
| [3] | It helps to have the relevant code open in a separate window while reading this article, in particular this section. Also keep in mind that many of the fields are implemented as actual Python objects (created by the CPython C API), so when I say a list or a dict it's an actual Python list or a dict, the interaction with which is via its C API. |
| [4] | The reason for the confusing name may be this list's later role in the compiler's flow in the creation of a code object. The co_varnames field of a code object contains the names of all local variables in a block starting with the parameter names (actually taken by the compiler from the ste_varnames field of the symbol table). |
| [5] | Look up "python private name mangling" on Google if you're not familiar with the mangling of private (marked by starting with two or more underscores) identifiers in Python classes. |
| [6] | You may be wondering why two passes are required and a single one isn't enough. It's a good question that ponders some philosophical and stylistic issues behind the practice of software development. My guess is that while the task could've been accomplished in a single pass, the multi-pass approach allows the code to be simplified at the cost of a very modest (if any) hit in performance. Sometimes splitting algorithms into multiple steps makes them much easier to grasp - readability and maintainability are important traits of well-written code. |
Consider, for example, this code:
def outer():
def inner():
bb = 1
return aa + bb + cc
aa = 2
return inner
Here, aa is free in inner, lexically bound to the aa defined in outer. But a one-pass algorithm would see inner before it ever saw the definition of aa, so to implement this correctly it would be forced to use some complex data structure to remember the variable uses it saw. With a two-pass algorithm, handling this case is much simpler.
| [7] | Throughout the code st refers to the symtable object that's being passed into functions, and ste to an entry object. |
| [8] | As an exercise, think whether this ensures that all generators returning values are caught as errors. Hint #1: what happens if the yield is found before the return? Hint #2: Locate the code for the handling of return statements by the first pass. |
| [9] | Here and on I'm presenting a somewhat simplified view of the second pass. There are further complications like variables declared global in enclosing scopes and referenced in enclosed scopes, that affect the results. I'm ignoring this on purpose to try and focus on the main aim of the second pass. Any source code has important special cases and trying to accurately summarize 1000 lines of code in a few paragraphs of text is an endeavor destined to fail. |